Real datasets
Here we provide several real datasets that can be used to test your operations in implemented in SpatialHadoop. All these datasets are extracted from public sources and can be freely used and redistributed. We highly recommend that you link to this page instead of copying the datasets because we will be updating these datasets and adding more.
If you find these datasets useful, consider citing our SpatialHadoop paper which made it possible to extract and process these big datasets.
- Ahmed Eldawy and Mohamed F. Mokbel, "SpatialHadoop: A MapReduce Framework for Spatial Data", In Proceedings of the IEEE International Conference on Data Engineering, ICDE 2015, Seoul, South Korea, April, 2015
@inproceedings{DBLP:conf/icde/EldawyM15,
author = {Ahmed Eldawy and Mohamed F. Mokbel},
title = {{SpatialHadoop: {A} MapReduce Framework for Spatial Data}},
booktitle = {31st {IEEE} International Conference on Data Engineering, {ICDE} 2015, Seoul, South Korea, April 13-17, 2015},
pages = {1352--1363},
year = {2015},
crossref = {DBLP:conf/icde/2015},
url = {http://dx.doi.org/10.1109/ICDE.2015.7113382},
doi = {10.1109/ICDE.2015.7113382},
timestamp = {Tue, 09 Jun 2015 07:58:12 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/icde/EldawyM15},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
TIGER 2015
TIGER datasets are all extracted from US Census Bureau TIGER files. The datasets published here are all extracted from the files of 2015. They are all converted from Shapefiles to CSV to be easily processed in SpatialHadoop. We are planning to provide built-in support of Shapefiles in SpatialHadoop which will allow processing shapefiles directly from their sources. Each line in the CSV file contains a shape represented in Well-Known Text (WKT) format followed by other meta information for this record. To process these records in SpatialHadoop, use the built-in data type TigerShape. You can do this by specifying the command line parameter 'shape:tiger' when calling one of SpatialHadoop functions.
For convenience, all files are provided in compressed format (.bz2). SpatialHadoop can process the compressed files directly. It will automatically decompress the files on the fly while being processed. You can also choose to decompress the files first and then work on the decompressed files directly. All file sizes showed below are for the uncompressed files.
| Dataset | Description | Size | Records | Schema | Overview | Download |
|---|---|---|---|---|---|---|
| AREALM | Area Landmark | 140MB | 129K Polygons | schema |  Click to enlarge |
Download [42MB download size] |
| AREAWATER | Area Hydrography | 2.1GB | 2.3M Polygons | schema |  Click to enlarge |
Download [613MB download size] |
| COUNTY | Counties | 149MB | 3,233 Polygons | schema |  Click to enlarge |
Download [47MB download size] |
| EDGES | All Edges Combined | 23 GB | 70 million polygons | schema |  Click to enlarge |
Download [5.7GB download size] |
| LINEARWATER | Linear Hydrography | 6GB | 5.8M Linestrings | schema |  Click to enlarge |
Download [4.1GB download size] |
| PRIMARYROADS | Primary Roads | 52 MB | 12,396 Linestrings | schema | 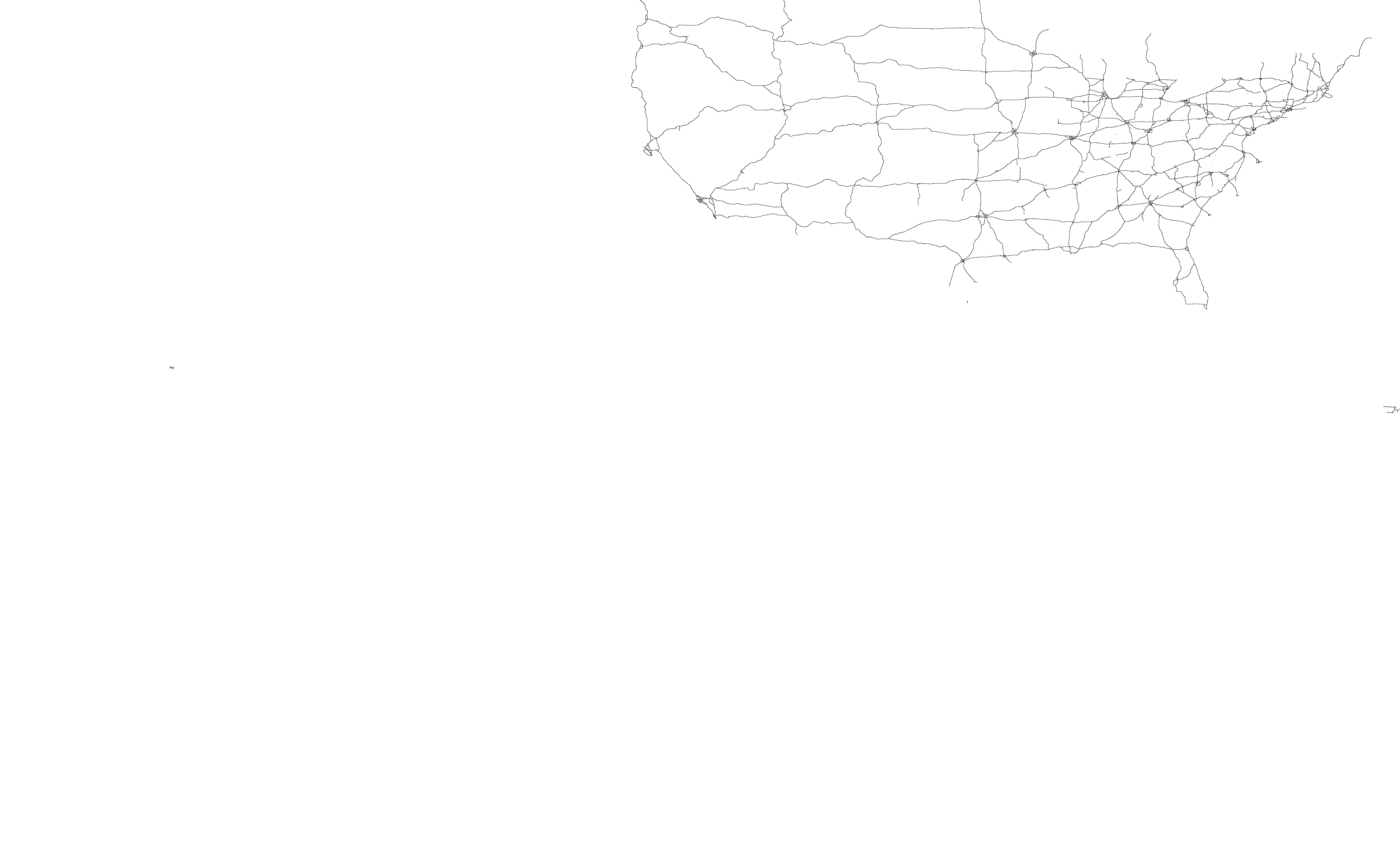 Click to enlarge |
Download [15MB download size] |
| RAILS | Rail roads | 79 MB | 181 million linestrings | schema |  Click to enlarge |
Download [23MB download size] |
| ROADS | Roads | 7.7 GB | 20 million Linestrings | schema |  Click to enlarge |
Download [2GB download size] |
| STATE | States | 17 MB | 56 polygons | schema |  Click to enlarge |
Download [6MB download size] |
| ZCTA5 | 5-Digit ZIP Code Tabulation Area | 1 GB | 33,144 Polygons | schema |  Click to enlarge |
Download [310MB download size] |
TIGER
Similar to the previous dataset but for the year of 2012. The geometry of shapes is represented in base-64-encoded Well-Known Binary (WKB).
| Dataset | Description | Size | Records | Schema | Overview | Download |
|---|---|---|---|---|---|---|
| arealm | Area Landmark | 406MB | 122K Polygons | schema |  Click to enlarge |
Download [99MB download size] |
| areawater | Area Hydrography | 6.5GB | 2.3M Polygons | schema |  Click to enlarge |
Download [1.4GB download size] |
| edges | All Edges Combined | 62GB | 72.7M Polygons | schema |  Click to enlarge |
Download [14GB download size] |
| linearwater | Linear Hydrography | 18.3GB | 5.9M Linestrings | schema |  Click to enlarge |
Download [4.1GB download size] |
| primaryroads | Primary Roads | 77MB | 13,373 Linestrings | schema | 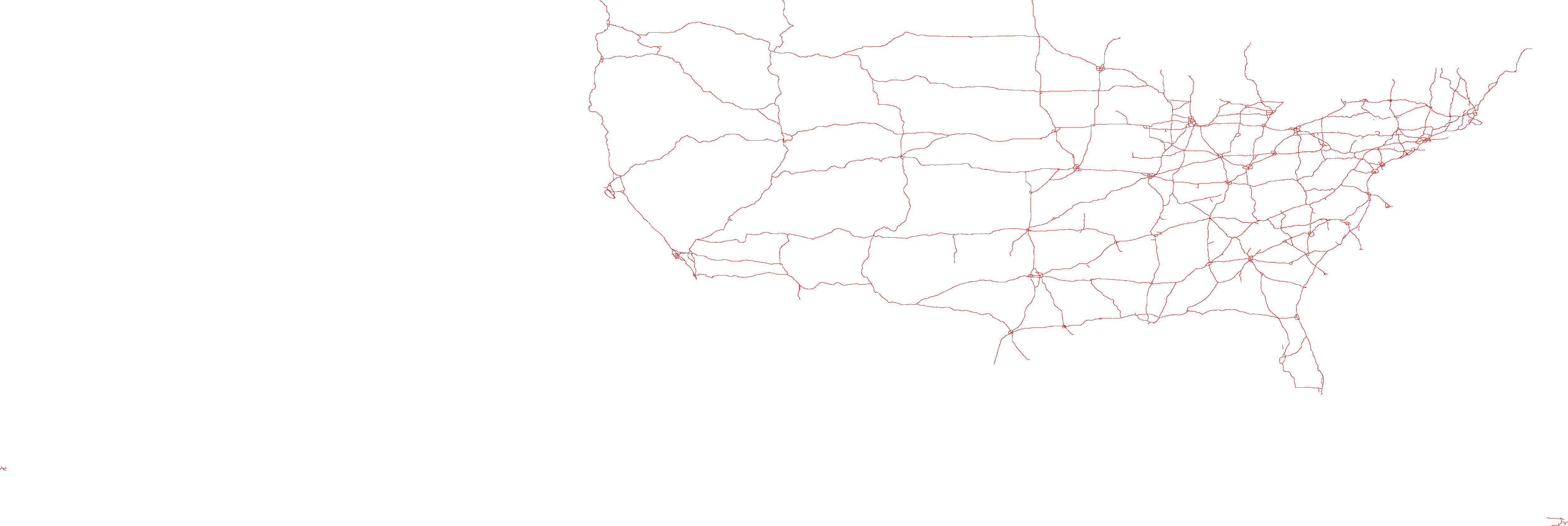 Click to enlarge |
Download [23MB download size] |
| zcta510 | 5-Digit ZIP Code Tabulation Area | 1.6GB | 33,144 Polygons | schema |  Click to enlarge |
Download [458MB download size] |
OpenStreetMap - New datasets
This dataset is extracted from OpenStreetMap and represents map features for the whole world. The data is extracted from one planet.osm file and all the data is converted to a text format for simplicity. All files are formatted as either comma-separated-values (CSV) or tab-separated-values (TSV) which make them ready to be used with Pigeon scripts. Similar to TIGER datasets, all files are compressed for convenience and can be processed without decompression by SpatialHadoop and Pigeon scripts.
| Dataset | Description | Size | Records | Schema | Overview | Download |
|---|---|---|---|---|---|---|
| All Nodes | All points on the planet | 96GB | 2.7 Billion records | schema | 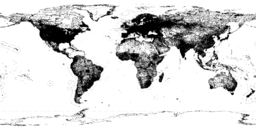 Click to enlarge |
Download [24.9GB download size] |
| All Objects | All extracted map objects | 92GB | 263M records | schema | 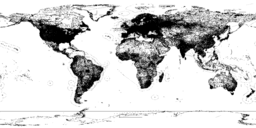 Click to enlarge |
Download [26GB download size] |
| Buildings | Boundaries of all buildings | 26GB | 115M records | schema |  Click to enlarge |
Download [6GB download size] |
| Cemetery | Boundaries of cemetery areas | 56MB | 193M records | schema |  Click to enlarge |
Download [17.4MB download size] |
| Lakes | Boundaries of water areas | 9GB | 8.4M records | schema |  Click to enlarge |
Download [2.7GB download size] |
| Parks | Boundaries of parks or green areas | 9.3GB | 10M records | schema |  Click to enlarge |
Download [2.9GB download size] |
| Postal codes | Boundaries of postal code areas (mostly cities) | 1.4GB | 171K records | schema |  Click to enlarge |
Download [477MB download size] |
| Road network | Road network represented as individual road segments | 137GB | 717M records | schema |  Click to enlarge |
Download [15.4GB download size] |
| Roads | Roads and streets around the world each represented as a polyline | 24GB | 72M records | schema |  Click to enlarge |
Download [6.7GB download size] |
| Sports | Boundaries of sporting areas | 590MB | 1.8M records | schema | 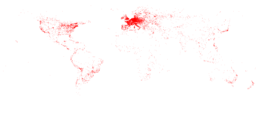 Click to enlarge |
Download [172MB download size] |
OpenStreetMap - Old datasets
This dataset is extracted from OpenStreetMap and represents map features for the whole world. The data is extracted from one planet.osm file and all the data is converted to a text format for simplicity. All files are formatted as Tab-Separated-Values which makes them ready to be used with Pigeon scripts. Similar to TIGER datasets, all files are compressed for convenience and can be processed without decompression by SpatialHadoop and Pigeon scripts.
In the nodes dataset, each node is identified by a node ID as stored in OpenStreetMap. The location of a point is represented by a pair of coordinates (longitude, latitude). The tags of a node are also stored as they appear in the planet file.
For the ways datasets, each way is identified by a unique ID as appears in OpenStreetMap planet file. The spatial information is stored as an OGC shape represented in Well-known text (WKT) format. Similar to nodes, the tags are stored as appearing in the planet file.
| Dataset | Description | Size | Records | Schema | Overview | Download |
|---|---|---|---|---|---|---|
| all_nodes | All points on the planet | 62.3GB | 1.7 Billion points | schema | 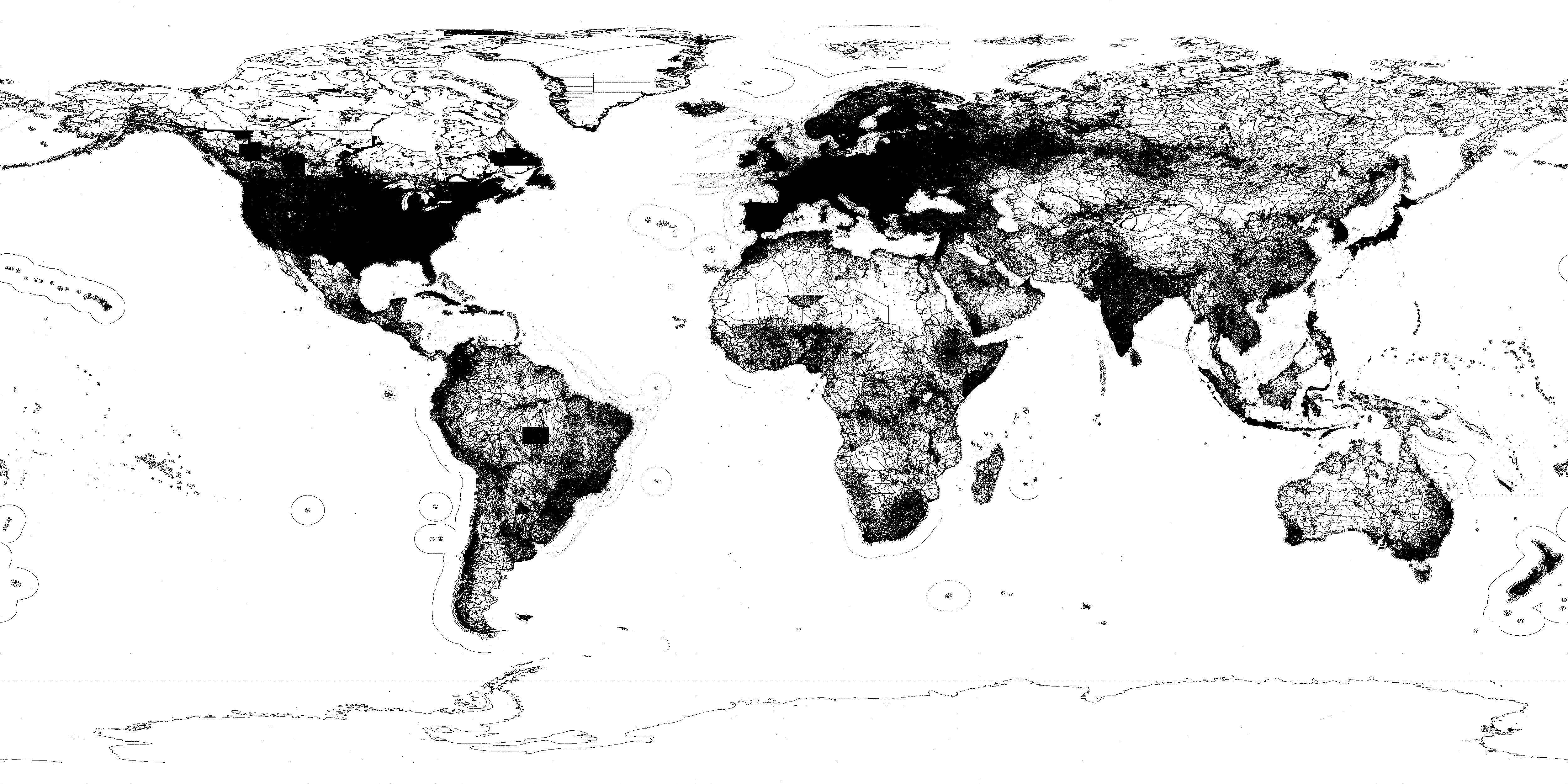 Click to enlarge |
Download [17GB download size] |
| all_ways | All ways on the planet | 59.6GB | 164M Polygons | schema | 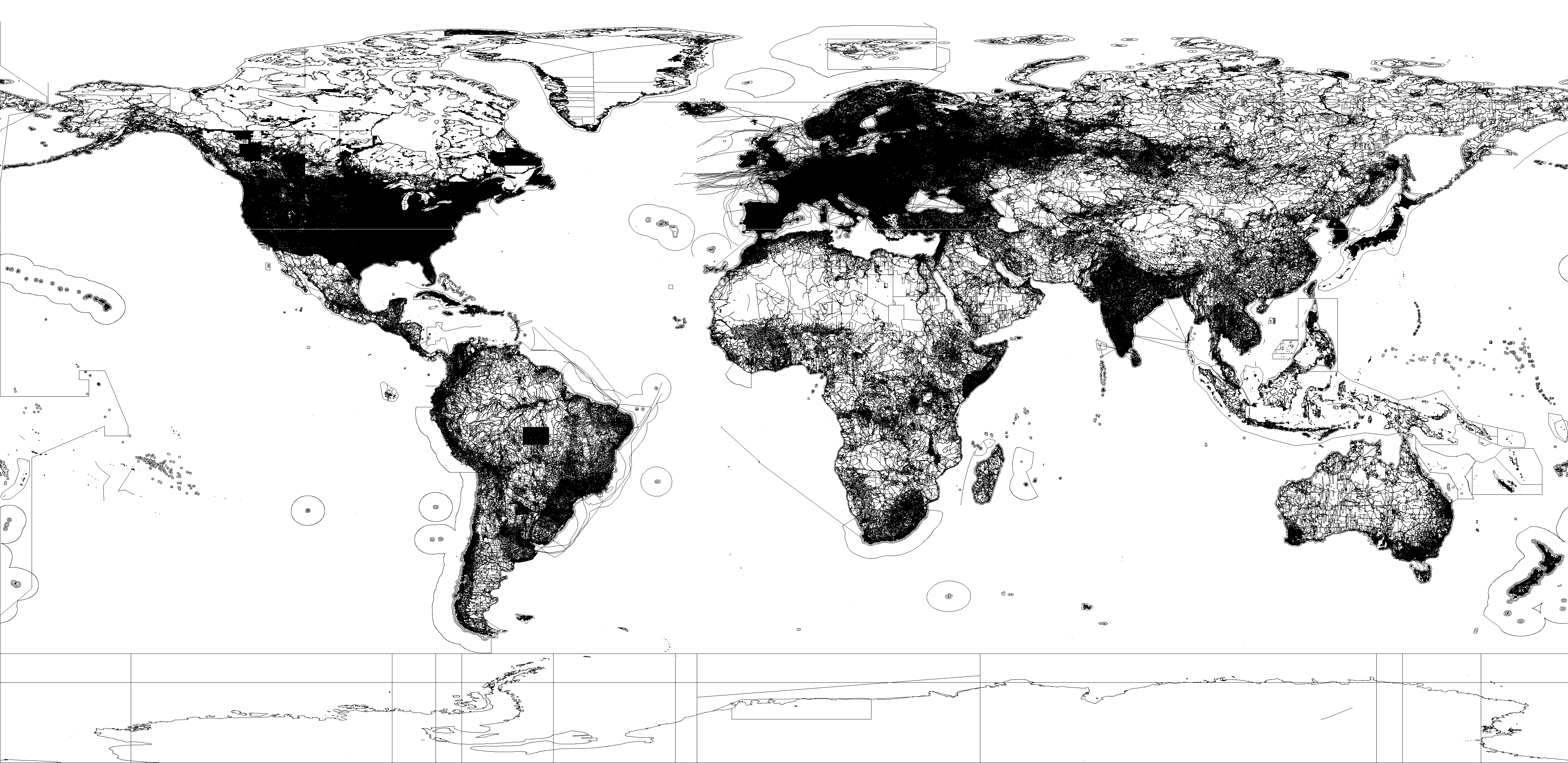 Click to enlarge |
Download [17GB download size] |
| cities | Ways that represent cities on the planet | 844MB | 542K Polygons | schema | 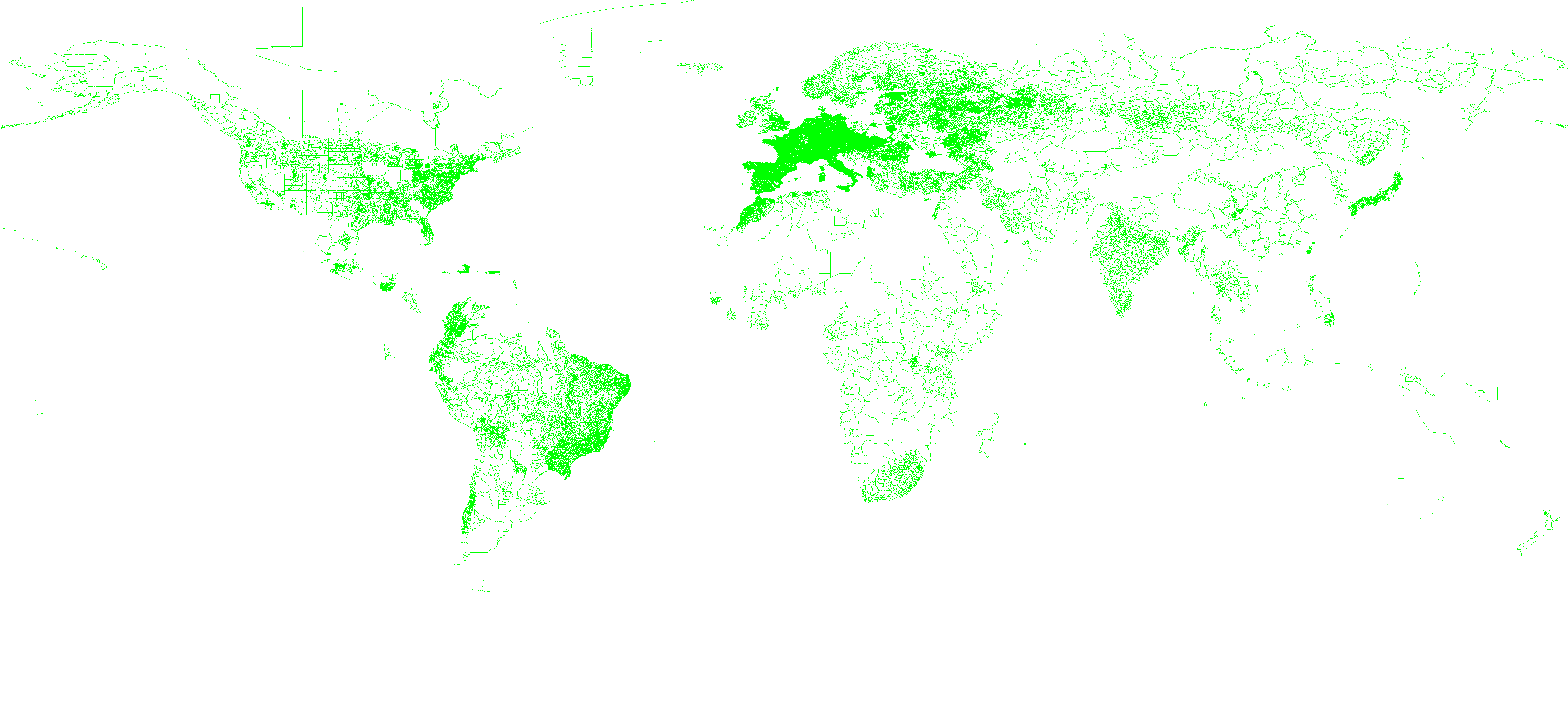 Click to enlarge |
Download [278MB download size] |
| lakes | Ways that represent lakes on the planet | 2.6GB | 4.3M Polygons | schema |  Click to enlarge |
Download [798MB download size] |
| parks | Ways that represent parks on the planet | 102MB | 234K Polygons | schema |  Click to enlarge |
Download [34MB download size] |
| rivers | Ways that represent rivers on the planet | 945MB | 555K Polygons | schema |  Click to enlarge |
Download [303MB download size] |
| roads | Ways that represent roads on the planet | 20.6GB | 59M Polygons | schema |  Click to enlarge |
Download [5.6GB download size] |